What Is a Canonical Tag? How to Set It Up and Use It Correctly for SEO
Published:
Last Updated:
Category: SEO & Content
Authors: Shusaku Yosa
Published:
Last Updated:
Category: SEO & Content
Authors: Shusaku Yosa
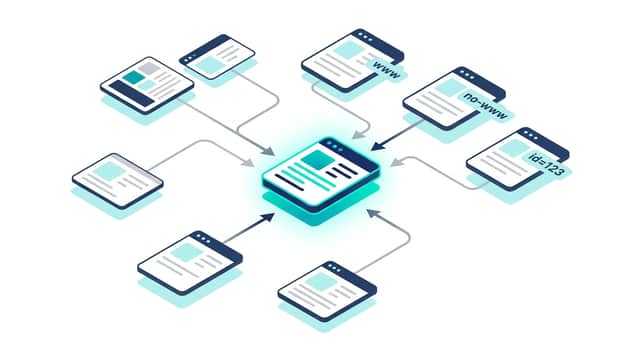
The canonical tag (rel="canonical") tells search engines which URL you want treated as the canonical page when identical or similar content exists at multiple URLs. It prevents evaluation from being split and consolidates it onto the page you're targeting.
That said, a canonical is not something that always produces the result you specify. It is one signal among several, and Google makes the final call. This article covers how canonical tags work, how to set them, when to use them, common mistakes, and how to verify them.
A canonical tag is written in the HTML head to tell search engines to evaluate a given URL as the canonical page. The word canonical means authoritative or standard.
When the same content is reachable at multiple URLs, search engines have to decide which one to index. In that situation, the evaluation that should accumulate on a single page gets split across several URLs instead.
Duplicate URLs arise unintentionally in cases such as these.
Note that having duplicate content on a site is normal in itself, and it does not on its own violate Google's spam policies or incur a penalty. The problems are split evaluation and the confusion it causes for user experience and measurement.
Google treats the canonical page as the main source for evaluating content and quality. Canonical pages are also crawled more frequently, while duplicate URLs are visited less often. URL canonicalization therefore affects not just the consolidation of evaluation but also crawl efficiency.
That said, crawl budget is only a serious concern for large sites in the range of a million pages, or sites with over ten thousand pages that update daily. For a site of typical size, thinking of it purely as preventing split evaluation is enough.
This is the most common method. Write the URL you want treated as canonical in the head of each page, in the following form.
<link rel="canonical" href="https://example.com/page-a">
Key points when writing it:
Non-HTML documents such as PDF and Word files have no head tag, so you return the canonical in an HTTP response header instead. This requires an environment where you can change server settings, and it is supported for web search results only.
URLs included in a sitemap indicate candidates for the canonical page, but this is a weak signal. Rather than relying on it alone, use it alongside canonical tags to strengthen the effect.
Redirects are the strongest canonicalization signal. When you want to retire an old URL and consolidate entirely onto a new one, use a 301 redirect rather than a canonical.
Choosing between a canonical and a 301 redirect is simple. If users need to see the duplicate page (you need to keep it), use a canonical; if they don't, use a 301 redirect.
Google states that combining these methods is more effective. Using two or more raises the likelihood that your preferred canonical URL appears in search results.
The prerequisite, however, is that you don't specify contradictory URLs across different methods. Avoid situations such as designating one URL in your sitemap while specifying a different URL for the same page via canonical.
For URLs carrying tracking UTM parameters or sort and filter parameters, specify the parameter-free URL as canonical when the content is the same. This matters especially on sites with faceted search, such as e-commerce and job listings.
When several pages have nearly identical content, such as product pages differing only by color or size, specify a representative page as canonical to consolidate evaluation.
If you serve separate desktop and mobile URLs rather than using responsive design, specifying the desktop version as the canonical page is the common approach.
On sites without duplicate pages, there's no need to force the issue. Google objectively determines a suitable URL to display even when no canonical URL is specified. In fact, Google explicitly states that while these methods are recommended, they are not required. That said, adding a self-referencing canonical across all pages is useful insurance against unexpected parameterized URLs.
This point deserves particular attention. There was once a convention of specifying page one as the canonical on page two and beyond of a listing, but Google's current recommendation is different.
For pagination, set a self-referencing canonical on each page: page two specifies page two's URL, page three specifies page three's. Each page lists different items, and Google treats each as a separate page. Consolidating onto page one risks the content on page two and beyond not being indexed.
Using noindex as a way to prevent a page from being selected as canonical within the same site is not recommended, because it blocks the page from Google Search entirely. Using rel="canonical" is the recommended method.
Likewise, blocking duplicate content with robots.txt is inappropriate. If a page isn't crawled, the canonical tag itself is never read, and you lose the evaluation each page carries.
For syndicated articles, pointing a canonical from the syndicated copy back to the original has fallen out of the recommended approach (though it is not prohibited). Cross-domain canonical specifications are frequently ignored. If you want to preserve the original article's evaluation, the recommended approach is to have the syndication partner apply noindex.
This is where the URL specified as canonical itself redirects elsewhere, or points to a URL that doesn't exist. It commonly happens when canonical updates are overlooked during site revisions or URL changes.
In a CMS such as WordPress, the theme or an SEO plugin may already output a canonical automatically. Adding one manually creates a duplicate, which results in search engines ignoring them. Check the source to see whether one is already output before you configure anything.
View the page source in your browser and search for rel="canonical" in the head. Confirm the intended URL is specified and that there aren't multiple instances.
This is the definitive check. Inspecting the target URL in Search Console's URL Inspection tool displays two things.
If the two match, things are working as intended. If they diverge, it means Google is not adopting the site's specification.
This message in Search Console's page indexing report is not an error. It reflects the normal state in which Google has read the canonical tag and is prioritizing the specified canonical page. If you set the canonical deliberately, no action is needed.
If you instead see "Duplicate, Google chose different canonical than user" or "Duplicate without user-selected canonical," duplicate pages exist without a canonical URL specified, so consider setting one.
Even with a canonical specified, Google may select a different URL as canonical. That's because a canonical is not a directive, only one signal among several.
In this case, you need to align the full set of signals indicating URL identity, not just the canonical tag on its own.
Note that before troubleshooting, Google recommends considering whether the URL it selected might actually be more useful for users.
The canonical tag prevents split evaluation across duplicate and similar pages and consolidates it onto the canonical page. The basics are to write it in the head with an absolute URL, one per page.
The key thing to keep in mind is that a canonical is a signal, not a directive. It works as intended only once you align the signals across the whole site, including internal links, sitemaps, and redirects, rather than just inserting the tag.
Watch out too for differences from older advice, such as setting a self-referencing canonical on each paginated page and not using noindex or robots.txt for canonicalization. After configuring, always check both the user-declared canonical and the Google-selected canonical in Search Console's URL Inspection tool.

An explanation of what kind of engagement model SEO consulting is. Covers the main support content, the benefits and dra...

Five principles for categorising your site, plus 10 structural design patterns including topic, problem, and industry ax...

SEO services fall into six types: consulting, content production, technical support, link building, tools, and in-house ...